Downloading Books Loaned from Archive.org
December 13, 2022
Archive.org makes available for download an extremely large collection of books. However, many of them cannot be downloaded, but only loaned for a short period of time, typically a single hour. This is annoying, because loans must be renewed all the time and because you need a reasonably fast internet access to consult loaned books. The online book viewer is also not nearly as convenient, fast and featureful as an offline PDF reader. Fortunately, it is still possible to download books that theoretically can only be loaned, with a few tools and a bit of Python code. I propose to show how to do this.
How are we going to proceed? We cannot access a loaned book as a PDF file, but we can still access its pages as images, since they are displayed within the online book viewer. Unfortunately, some Javascript code has been added to disable right clicks on book pages, which makes it impossible to do a right click → “Save image as” for downloading a book page. It might be possible to circumvent this by writing a browser extension, but there is a simpler solution. Indeed, Web browsers use a local cache for storing images and other files, so as to avoid downloading them again and again whenever possible. Provided our browser is properly configured, we can download all pages of a book by turning them one by one in the archive.org book viewer, and then create a PDF file out of them.
1. Initial Setup
Which Web browser should we use? Google Chrome is inconvenient, because it does not store cache entries as regular files and uses instead some kind of database or custom file format. Firefox, by contrast, stores cache entries as regular files in a single directory and names them according to the output of some hash function. We will thus use Firefox instead of Chrome. On Linux, its cache directory is located at ~/.cache/mozilla/firefox/PROFILE/cache2/entries, where PROFILE is a profile name like 6fmyuopl.default-release.
A cache does not grow unbounded, such that entries might be evicted from it when hitting a size limit. You might thus need to enlarge the Firefox cache capacity to make it large enough to store the pages of a full book, plus some extra space. First enter about:config in the URL bar, and search for the option browser.cache.disk.capacity. This is the maximum capacity of the cache, expressed in KB. The default value on my computer is 256,000, thus 256 MB, which is plenty enough for storing all pages of a book.
Now that the cache is properly configured, go to archive.org and borrow the book you want to download.

Move to the very first page of the book if need be—sometimes the book viewer displays the title page instead of the front cover initially. Set the one-page view mode, then zoom in many times by clicking the appropriate button in the book viewer until the image becomes very pixelated. The purpose of using a one-page view and to zoom like this is to ensure we get the best possible image resolution. Indeed, book pages are available in at least three different resolutions, and the best one will only be selected if you zoom in enough. You should end up with a view like the following:
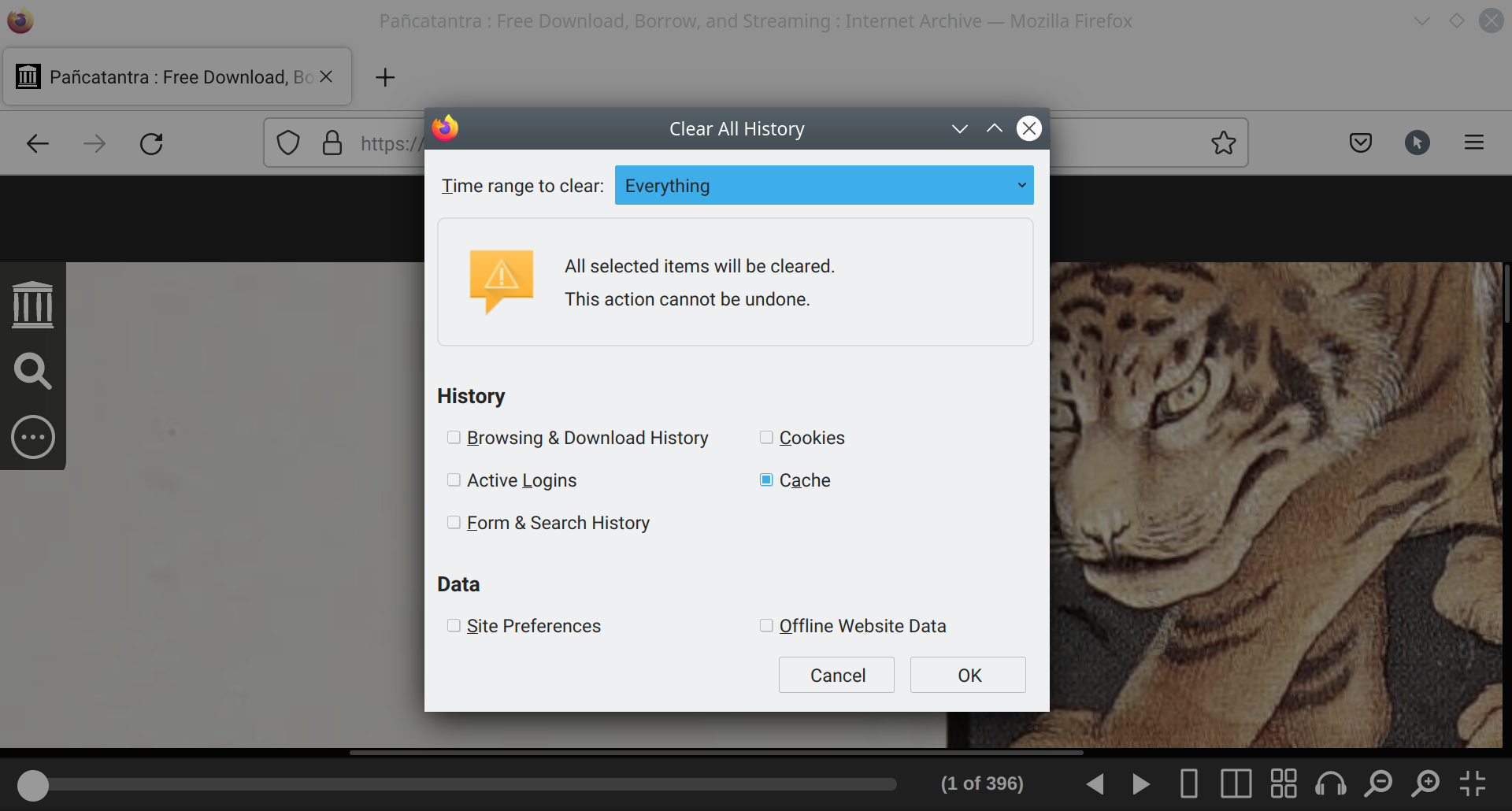
At this point, we need to clear Firefox’s cache so that we have enough space to store the whole book. Open the “Clear history” dialog with Ctrl+Shift+Del or through the menu, adjust options so that they match the figure below, then click OK.
2. Downloading Pages
We can now populate the browser’s cache with the contents of the book. To do so, we just need to turn its pages, one by one, from start to end, by tapping the right arrow key, for instance. Of course, we are not going to sit there manually tapping the same key hundreds of times. Instead, we will write a small program that does it for us.
Many tools are available for simulating keyboard input, like AutoHotkey on Windows. On Linux, we can use the kernel uinput interface, which makes it possible to create virtual input devices. It can be used with system calls directly, but there is a convenient Python wrapper that makes the process somewhat easier. You can install it with:
sudo pip3 install evdevFor turning pages, we will use a script named turn_pages.py which contains the following Python code:
import time
from evdev import UInput, ecodes as e
dev = UInput({e.EV_KEY: [e.KEY_RIGHT]})
while True:
time.sleep(10)
dev.write(e.EV_KEY, e.KEY_RIGHT, 1) # press
dev.syn()
dev.write(e.EV_KEY, e.KEY_RIGHT, 0) # release
dev.syn()In the above, we start by creating a virtual input device “dev” that behaves like a keyboard that supports a single key, namely “KEY_RIGHT” viz. the right arrow key. We could also support more keys, simulate clicks, etc., by modifying this initialization code.
We then simulate a right arrow key tap every ten seconds. The “dev.write” method here simulates a key press or key release event. The “dev.syn” method is comparable to a commit in a database management system; it tells the kernel to take into account the last event—or set of events, for mouse movements.
The ten-seconds interval might seem too long at first sight. It is however important to have a reasonable delay between page changes, to prevent the code from tripping up and miss pages if your internet has hiccups or if a rogue program slows down your computer. We also want not to consume too much bandwidth from the servers of archive.org, because this is about as rude as helping yourself to your host’s fridge when invited for dinner.
But let us proceed and download the book’s pages. First run the above script:
python3 turn_pages.pyThen switch to the Firefox window and click on the current page to make it get the focus. If everything works well, you should see pages turn automatically. It might take a while to finish, depending on the length of the book, so you better do something else in the meantime. Also note that you might have to loan the book again and restart the page turning process if one hour is not enough to turn all the pages.
3. Extracting Pages from the Cache
After the end of the book has been reached, we need to extract its pages from the browser’s cache and to rename the corresponding files in such a way that their natural sort order matches their actual order in the book. In my experience, pages of loaned books are always encoded as JPEG images. We will thus extract all JPEG images from the cache directory and sort them by date of creation viz. in the order they were downloaded.
To determine if a file is a JPEG image, we will use libmagic, which provides access to a database of “magic” signatures viz. sequences of bytes that typically appear at the beginning of a file and that describe what kind of data this file contains. We will use a Python wrapper, that can be installed like this:
sudo pip3 install python-magicFor extracting pages, we will use a script named extract_pages.py which contains the following code:
import os, glob, sys
import magic
root = "~/.cache/mozilla/firefox/*.default-release/cache2/entries"
root = glob.glob(os.path.expanduser(root))[0]
out_dir = "."
if len(sys.argv) > 1:
out_dir = sys.argv[1]
os.makedirs(out_dir, exist_ok=True)
files = []
for name in os.listdir(root):
path = os.path.join(root, name)
mime = magic.from_file(path, mime=True)
if mime != "image/jpeg":
continue
created = os.stat(path).st_ctime_ns
files.append((created, path))
files.sort()
for page, (_, in_path) in enumerate(files, 1):
with open(in_path, "rb") as f:
data = f.read()
out_path = os.path.join(out_dir, "%05d.jpg" % page)
with open(out_path, "wb") as f:
f.write(data)In the above, we first try to figure out programmatically what is the location of the cache directory on our computer and set “root” to this value. You might need to set this variable manually if this fails or if you use several Firefox profiles. We then set “out_dir” to a directory name that might be given as argument to the script and to which the book pages will be copied.
After that, we create a list of all JPEG images within the cache directory, together with their creation time in nanoseconds. We do not use the creation time in seconds (st_ctime) because book pages are in fact downloaded by pairs—probably to support facing pages—in well under a second. We then sort the images list by order of creation time and copy all images to the output directory, renaming them in the process to zero-padded integers that represent their position in the sorted list. JPEG images in “out_dir” thus end up sorted by time of download, which is the order of the pages in the book (save for the front cover, see below).
But let us proceed and extract the book’s pages. Run the above script with:
python3 extract_pages.py pagesOnce this is done, check the contents of the “pages” directory the script created and delete all JPEG images that are not book pages. Depending on when exactly you cleared Firefox’s cache, there might be lower resolution versions of some pages, which you should remove, too. It is not necessary to rename the remaining files; all that matters is that pages are sorted as in the book. Furthermore, if you cleared the cache exactly as prescribed above, the first page of the book should come just after the second one. Rename it to 00000.jpg, for instance, to make it come first, lexicographically speaking.
You might also want to ensure that the number of remaining images matches the number of pages in the book. Note however that the book viewer of archive.org sometimes uses several numbering systems to match those used in the physical book. If you go to the very first page of the book, the number of pages indicated at the bottom of the book viewer is apparently the actual page count viz. the number of images there should be within the “pages” directory created above. This number might change if you move further in the book. Compare for instance the two screenshots below:

4. Creating a PDF
Now that we have cleaned up the “pages” directory, it remains to
merge all the JPEG images it contains into a single PDF file. For doing
that, we will use img2pdf, which you can download like
this:
sudo pip3 install img2pdfNow run the command below:
img2pdf -o book.pdf pages/*.jpgThis creates a PDF file “book.pdf” that contains all the images passed as positional arguments on the command line, in the order they are given. At this point, you can delete the “pages” directory and start reading the book.
However, we might additionally want to add a text layer to the book’s PDF, so as to make it searchable both from PDF readers and from desktop search engines like recoll. For doing this, we need an OCR tool, the most convenient of which, to my knowledge, is ocrmypdf. It does not do any OCR on its own, but instead wraps the tesseract OCR library. Check the documentation I just linked to for installation instructions. Optionally, you might want to install the JBIG2 encoding library, as it helps to reduce the size of PDF files.
To operate correctly, the tesseract OCR library needs to access models trained on the specific language or script it will be asked to recognize. You can download OCR models for several languages from the tessdata repository. Model files should be copied to the tesseract data directory, which is typically /usr/share/tessdata.
Once you have installed the models for the languages or script you want tesseract to recognize, you can add a text layer to “book.pdf” like this:
ocrmypdf -l eng book.pdf book.pdfThe -l flag is used to provide model names—typically,
three-letters language codes like “eng” and “fra”, or script names like
“Latin”. For multilingual texts, you can pass several models names by
joining them with a “+” character; “eng+fra+ita”, for instance, would be
appropriate for a book that includes English, French and Italian text.
You might also want to pass other options to ocrmypdf, to reduce the PDF
size in particular. See ocrmypdf’s documentation for more details.
When ocrmypdf returns, you now have a searchable book.